By Thomas de Marchin, Pierre Lebrun, Jean-François Michiels and Haleh Nekoee
While many drugs on the market are synthesized chemically (small molecules), biologics—drugs produced by living organisms—are gaining prominence. The culture of living organisms is crucial for producing potent therapeutic proteins and antibodies, often presenting a critical challenge due to the inherent variability and difficulty in growing cells compared to the predictability of synthetic chemistry.
The Power of Digital Twins for process optimisation
A digital twin is a dynamic virtual replica of a physical system—such as a bioreactor or a chromatographic purification step—that evolves in real-time alongside its real-world counterpart (Figure 1). By integrating live data, historical records, and predictive models, digital twins typically enable:
- Real-time process optimization: closed-loop control systems that self-adjust to maintain optimal conditions.
- Process understanding and risk mitigation: simulate “what-if” scenarios to avoid costly production failures.
- Accelerated development: reduce reliance on physical experiments by testing hypotheses virtually.
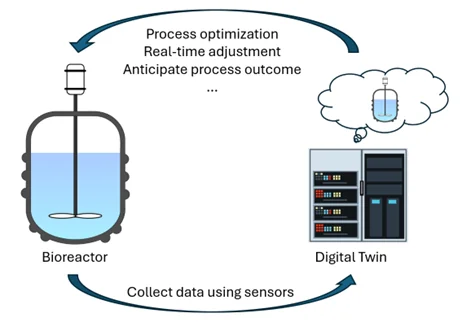
Figure 1: Illustration of a digital twin.
Approaches to model digital twins include mechanistic models physical law, data-driven models, and hybrid models that blend both.

Figure 2: Mechanistic, hybrid and data-driven models
1. Data-Driven Models – or black box
Data-Driven models work by fitting function approximators (mathematical lines or curves) to experimental data, typically using linear models and more sophisticated machine learning algorithms. Their strength lies in identifying statistical patterns quickly, making them ideal for short-term monitoring of well-characterized processes. However, these models do not mimic real-world biological or physical mechanisms, offering little understanding and insight into why certain outcomes occur. Also, Data-driven models have difficulties using expert knowledge and have a tendency to overfit to the data they were trained on. While they predict well within their training data, they struggle to extrapolate beyond it, such as forecasting behaviour in untested bioreactor scales. This lack of interpretability also complicates regulatory audits, as their predictions cannot be traced back to biological and physical principles.
2. Mechanistic Models – or white box
Mechanistic models are constructed completely based on known physical laws that describe biological or physical mechanisms, such as nutrient consumption rates or metabolic pathways. Their key strength is interpretability, allowing scientists to directly link variables like glucose uptake to cell growth rates. They also perform reliably in novel scenarios, such as scaling up bioreactors, because they adhere to fundamental biological and physical laws. However, while mechanistic models are transparent, they often oversimplify complex systems and miss complex biological behaviour. The challenges to create and adjust such models that would account for so many potentially impactful variables are real.
3. Hybrid Models – or grey box
Hybrid models merge data-driven and mechanistic models, combining the strengths of both approaches. They achieve robust extrapolation while capturing hard-to-model behaviours, such as cell growth rate evolution and nutrient consumption in response to changing environmental conditions. While their initial development is more complex, hybrid models can reduce the experimental design and allow reusing existing models for new product development. They also excel in real-time optimisation, predictive scale-up and they ease regulatory compliance by improved characterization with a better understanding of the process (FDA Stage 1) and development of real-time control limits for a specific batch (FDA Stage 3).
Case Study: Bioreactor cell culture Digital Twin
Cell and living organisms are often grown in bioreactors. In the so-called batch approach (Figure 1), cells are inoculated in a cultivation medium containing all nutrients required by the cells.
While cell cultures are usually modelled using empirical data-driven models, there are incentive to develop hybrid models allowing to get a better understanding of the process and reduce the number of experiments.
Figure 2 illustrates a probabilistic hybrid model designed to simulate the dynamics of a batch bioreactor. This model captures the evolution of biomass, glucose concentration, and product formation in the medium, driven by cell growth and key process parameters such as temperature, initial glucose concentration, and agitation rate. The approach integrates a Bayesian deep neural network that takes these process parameters as inputs and predicts biological parameters such as rates, yields, and plateau levels for biomass and product formation. These predicted parameters then serve as inputs to a system of ordinary differential equations (ODEs), which compute the dynamic responses of the bioreactor over time.
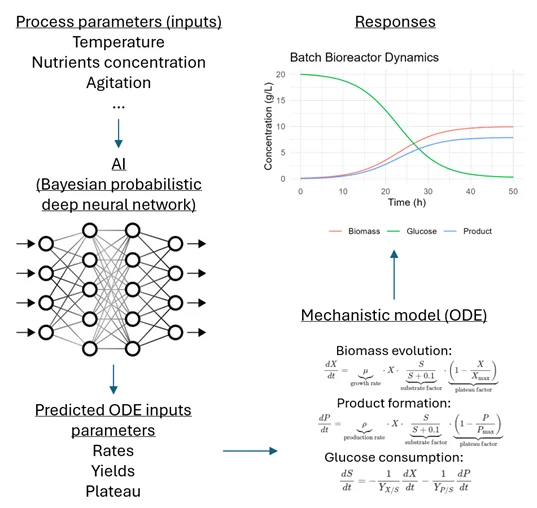
Figure : Hybrid model example for a batch bioreactors
A critical advantage of using a probabilistic Bayesian neural network is its ability to estimate not only the mean or best prediction but also the uncertainty associated with these estimates. This uncertainty quantification is essential because, in practical applications—especially in drug development where experiments are extremely costly—knowing how much to trust a model’s prediction can be as important as the prediction itself. For example, an AI system used in medical diagnosis should not only identify a tumor but also provide the uncertainty for its prediction, allowing ambiguous cases to be flagged for further human review and thus reducing the risk of misdiagnosis. Despite the widespread use of neural networks in drug development, incorporating and expressing uncertainty remains rare, which limits the reliability and safety of AI-driven decisions in this high-stakes field.
To illustrate our hybrid model proof of concept, twenty-seven experiments were simulated to investigate the effects of initial glucose concentration (5–10 g/L), temperature (20–40°C), and agitation rate (150–350 rpm) on biomass growth, product formation, and glucose consumption over time. Our hybrid model was trained on 21 experiments (training dataset, see Figure 3) , using the PyTorch framework in combination with the probabilistic programming library Pyro. The model’s generalization capability was evaluated using predictions for six independent test experiments (test dataset, Figure 4). This validation approach ensures robustness against overfitting and confirms reliable performance on unseen data. The close agreement between model predictions and experimental measurements demonstrates the model’s accuracy in capturing the underlying biological and kinetic processes. The prediction bands presented as shaded area illustrate the captured uncertainty, and is coherent with the natural data variability.
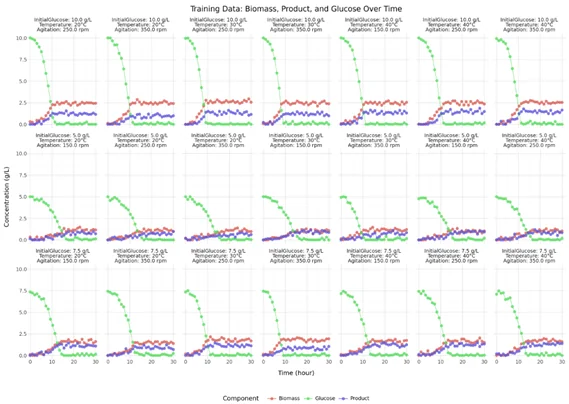
Figure : Training dataset. Curves represent the temporal evolution of biomass, glucose, and product concentrations under varying process parameters (agitation rate, temperature, and initial glucose concentration).
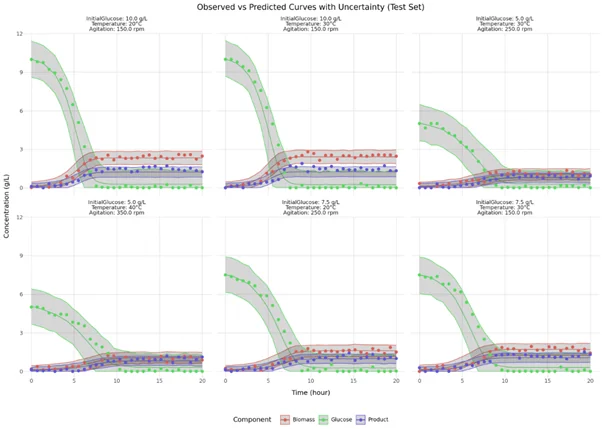
Figure : Test dataset and model predictions. Solid lines represent mean predictions, with shaded areas indicating 95% uncertainty intervals.
Conclusion
Hybrid modelling represents a breakthrough approach for digital twins in drug development, offering advantages over purely empirical or mechanistic methods. Our hybrid model demonstrates the ability to predict experimental outcomes—with uncertainty estimation—even when mechanistic knowledge only partially describes the studied process. This capability enables real-time optimization, predictive scale-up, and streamlined regulatory compliance, ultimately accelerating drug development while reducing experimental requirements. In upcoming blog posts, we will compare hybrid modelling with traditional data-driven approaches, demonstrating how our method requires fewer experiments through Intensified Design of Experiments (iDoE) which introduce shifts in process parameters within a single experiment, effectively compressing multiple DoE combinations into a smaller set of experiments. Additionally, we will expand our modelling framework to encompass diverse bioreactor technologies, including Fed-Batch, Chemostat, and Perfusion systems.
What specific challenges or opportunities in digital twins or hybrid modelling would you like us to explore next? Let us know by filling the form below!
Biography
Thomas de Marchin is Associate Director of Statistics and Data Science at Cencora PharmaLex, where he applies advanced statistical methodologies and machine learning algorithms to optimize drug discovery and manufacturing efficiency. With deep expertise in regulatory compliance—particularly FDA and GMP standards—he bridges the gap between complex analytical approaches and practical pharmaceutical applications. Known for his collaborative leadership style, Thomas partners with research scientists, process engineers, and quality teams to translate data insights into actionable strategies that drive innovation while maintaining rigorous industry standards.
Note:
Results were generated with the assistance of BioWin ASBL and the financial support from the Region, in accordance with the provisions of the Grant Agreement (Convention 8881 ATMP Thérapie cellulaire).